Convolutional Neural Networks
★ 1. Convolutional Layer
★ 2. Pooling Layer
Convolutional Neural Networks

(Convolutional Layer - Activation Function - Pooling Layer) 반복 → Fully Connected Layer
1. Convolutional Layer
① input: 32 x 32 x 3 image
② Filter
- Receptive Field라고 부르기도 함
- 이미지의 크기보다 작은 크기를 가지나, depth는 같아야 함
- Filter는 이미지의 전체를 돌면서 내적을 수행하고 bias를 더함


③ Output: 2-dimensional activation map
- 사용한 Filter의 개수에 따라 output의 depth가 결정됨
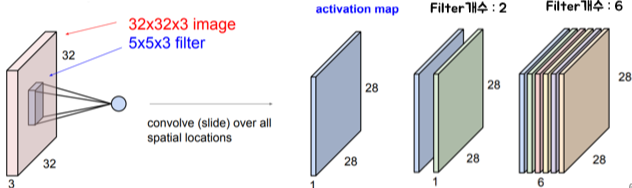
- Filter들은 input에서 각각 다른 특징을 찾아냄

- Spatial Dimension

Input size: 7x7
Filter size: 3x3
ⓛ Stride: 1일때, Output의 size는 5 x 5
② Stride: 2일때, Output의 size는 3 x 3
In general,
Input size: NxN
Filter size: FxF
Output size: (N-F)/Stride + 1
- Zero Padding
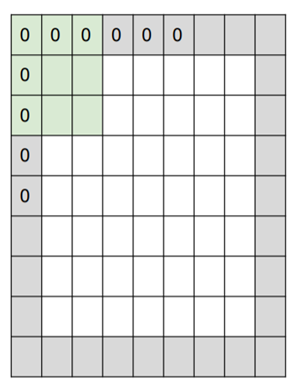
Input의 가장자리에 0을 추가시킴으로써 Filter를 통과했을 때 Output size가 유지된다. Filter의 크기에 따라 Output size 유지에 쓰이는 zero pad의 수가 다르다.
Input size: 7x7
Stride: 1
ⓛ Filter size: 3x3, Zero pad: 1 → Output size: 7x7
② Filter size: 5x5, Zero pad: 2 → Output size: 7x7
③ Filter size: 7x7, Zero pad: 3 → Output size: 7x7
Q1. zero padding을 하면 가장자리에 상관없는 값들이 들어가는 것이 아닌가?
A. ㅇㅇ. 인위적인 값이 들어가는 대신 크기 유지가 가능
Q2. Non-square image일 때 stride 값의 가로와 세로를 다르게 설정해야 하는가?
A. 상관없는데, 보통 같은 값을 씀
종합해서 정리하면 다음과 같다.

[Examples]
- Input: 32x32x3
- Filter: 5x5 size가 10개
- Stride: 1, Pad: 2
- Output volume size: (32-5+4)/1+1 = 32 → 32x32x10
- Number of parameters in this layer
: 5x5x3 + 1 = 76 parameters (1: bias)
76x10 = 760개
2. Pooling Layer

Pooling layer에서는 Spatial size를 작게 만들어 input을 간단하게 만든다. 각각의 activation map에 독립적으로 작용한다.

- Max Pooling
Pooling Layer에서는 오버랩을 허용하지 않는 stride를 설정하는 것이 일반적이다. 각 filter에서 가장 큰 값만 남기는데 이미지의 부분에서 특징적인 부분을 뽑아 요약한다고 생각할 수 있다. max pooling을 하고 나서도 depth는 변하지 않는다. 가장 일반적으로 2x2 filters에 stride가 2인 max pooling을 많이 사용한다고 한다.
'cs231n' 카테고리의 다른 글
| lec7. Training Neural Networks, Part 2 (0) | 2021.07.27 |
|---|---|
| lec6. Training Neural Networks, Part I (0) | 2021.07.09 |
| lec4. Backpropagation & Neural Networks (0) | 2021.07.08 |
| lec3. Loss Functions & Optimization (0) | 2021.07.08 |
| lec2. Image Classification (0) | 2021.07.08 |




댓글