How do I Entity Resolution?
- Source normalization: 데이터를 깔끔하게 정리, 여러 소스에서 하나의 스키마로 맞춤. 이 스키마에서 사용되는 피처(column)들은 나중에 매치되는 짝들을 평가하는데 사용됨
- Featurization and blocking key generation: blocking key를 위한 피처 생성. blocking key는 매치되는 레코드들 사이에서 공유되는 타겟화된 토큰임. 검색 공간을 N^2에서 더 계산이 수월하도록 제한하기 위함
- Generate candidate pairs: blocking join key를 사용해서 후보 pair 생성. 기본적으로 blocking key에 대한 self-join임. 그래프 데이터 구조에서 실행됨 (레코드: 노드, 매칭정보: edge)
- Matching socring and iteration: 후보 pair가 실제로 매치되었는지 match scoring function을 통해 결정. rule-based가 될 수 있는데, 일반적으로 non-linear한 decision boundary에서 적응하고 최적화할 수 있는 학습 알고리즘으로 더 잘 구현됨.
- Generate entites: 그래프에서 매치되지 않은 엣지들을 제거하고, resolved-entities와 각각의 소스 레코드들에 연관된 맵핑을 생성함
3. Generate candidate pairs
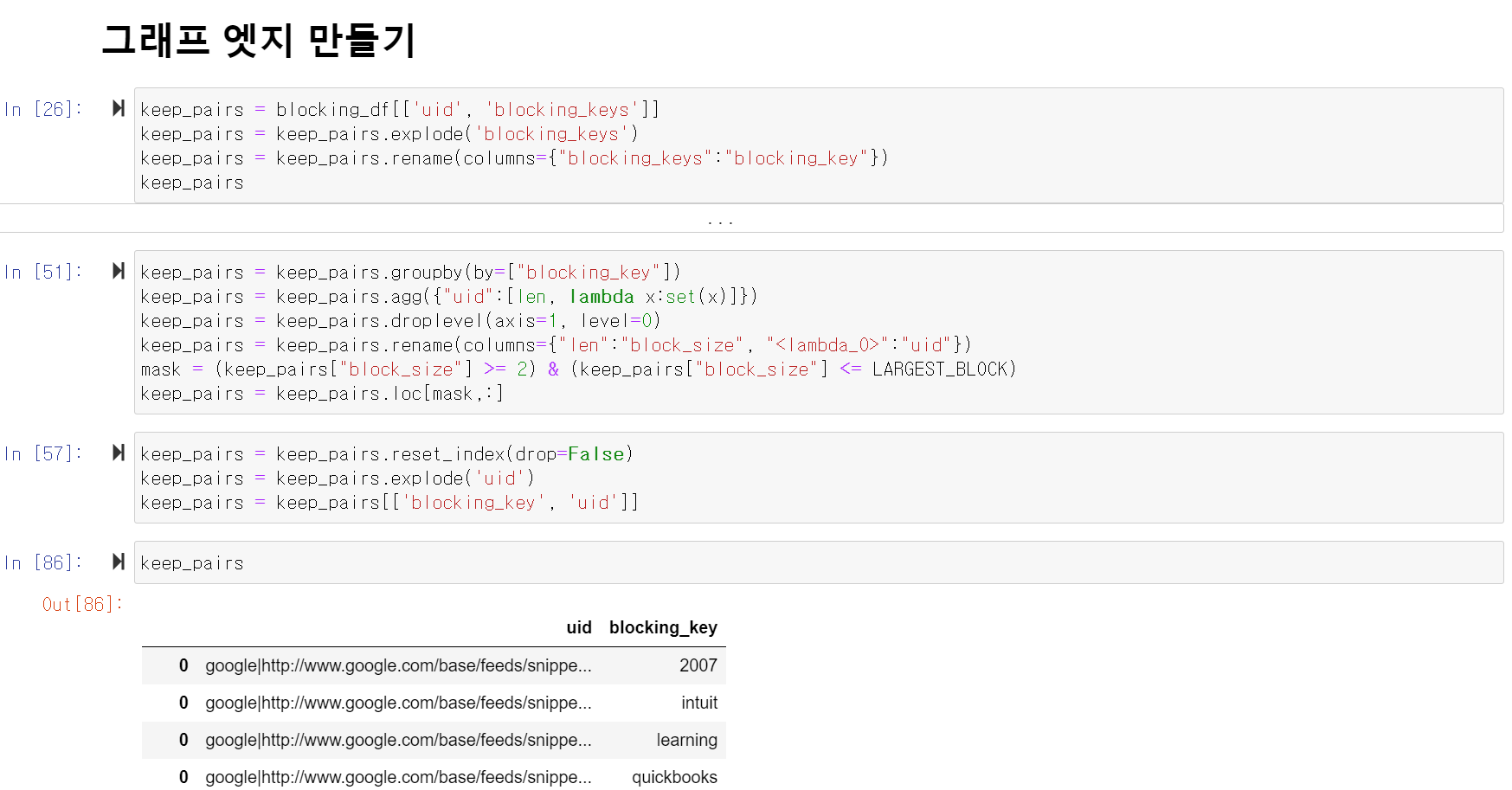
후보 pair 생성은 기본적으로 blocking key의 self join이다. 여기에 구현을 효율적으로 하고, 확장성을 좋게 하기 위해 몇 가지가 추가된다.
그래프 노드 생성
1. blocking join으로부터 나온 자료구조는 그래프로 모델화될 수 있다. 여기서 레코드들은 노드이고, 후보 pair들은 edge가 된다. 그래프로 모델링하는 것은 기존의 table 구조를 사용하는 것보다 downstream 계산에서 훨씬 더 성능이 뛰어나다.
2. 얼마나 큰 block을 가질 수 있는지에 대한 상한을 구하자. 이것은 낮은 특정성을 가진 blocking key가 연결이 매우 많은 노드를 만드는 것을 막는다. 노드에 과도하게 연결이 생길 경우 성능에 부정적으로 영향을 미치는 왜곡된 파티션을 결과로 한다. threshold는 특정 응용과 데이터세트에 따라 다르지만, 핵심 포인트는 단일 개체로 분해되어야 하는 레코드의 합리적인 수이다. 이 예제에서는, 동일한 실제 제품을 참조하는 제품 목록이 100개가 넘는다는 것을 상상하기 어렵기 때문에 상한을 100개로 선택했다.

그래프 엣지 생성
3. blocking key에 대해 self-join을 할 때, node의 순서는 pair를 바꾸지 않으므로 순서가 반대로 지정된 모든 쌍은 중복 제거되어야 한다. 마찬가지로 같은 노드를 비교할 필요가 없기 때문에, (같은 노드)-(같은 노드)도 제거되어야 한다. 예제에서 처음 조인을 했을 때 60만개에 가까운 pair가 생겼는데, 필요없는 pair를 제거해준 후 23만개로 줄어들었다. 노드 수가 4600개니 한 노드당 50개 정도의 pair가 나왔는데 좀 많은 것 같다.


Neo4j로 그래프 로드
만든 후보 그래프를 Neo4j를 이용해 시각화해보았다.
Product가 위에서 만든 노드이고, Matches가 후보 pair이다.



'지식그래프' 카테고리의 다른 글
| Entity Resolution 개념 (2) (0) | 2022.09.01 |
|---|---|
| Entity Resolution 개념 (1) (2) | 2022.08.31 |
| [논문리뷰] FoodKG: A Semantics-Driven Knowledge Graph for Food Recommendation (0) | 2022.07.18 |



댓글